


Note
Click here to download the full example code
Time Series Classification with InceptionTime¶
Author: Vincent Scharf
In this tutorial, we are going to learn how to train an InceptionTime style classifier.
For this tutorial, we will use the Beef dataset available at the UEA & UCR Time Series Classification Repository [Dau et al., 2019]. The beef dataset consists of four classes of beef spectrograms, from pure beef and beef adulterated with varying degrees of offal. The spectrograms are univariate time series of length 470. The train- and test set consist of 30 sampels each.
Note
torchtime provides easy access to common, publicly accessible
datasets. Please refer to the official documentation for the list of
available datasets.
We will do the following steps in order:
- Load the Beef training and test datasets using
torchtimeand impute potential missing values
- Load the Beef training and test datasets using
Define an InceptionTime style classifier
Define a loss function
Train the network on the training data
Test the network on the test data
1. Load and Normalize Beef¶
Using torchtime, it’s extremely easy to load datasets contained in the UCR & UEA
time series classification repository.
import torch
import torch.utils.data as data
import torchtime
import torchtime.transforms as transforms
The output of torchtime datasets can contain NaN values.
We impute those missing values using transforms.Nan2Value().
Note
If running on Windows and you get a BrokenPipeError, try setting the num_worker of torch.utils.data.DataLoader() to 0.
transform = transforms.Compose(
[transforms.Nan2Value()])
batch_size = 4
trainset = torchtime.datasets.UCR(root='./data', name="Beef", train=True,
download=True, transform=transform)
trainloader = data.DataLoader(trainset, batch_size=batch_size, shuffle=True, num_workers=2)
testset = torchtime.datasets.UCR(root='./data', name="Beef", train=False,
download=True, transform=transform)
testloader = data.DataLoader(testset, batch_size=batch_size,
shuffle=False, num_workers=2)
classes = ('unadulterated', 'heart', 'kidney', 'liver', 'tripe')
Downloading http://www.timeseriesclassification.com/Downloads/Beef.zip
Downloading http://www.timeseriesclassification.com/Downloads/Beef.zip to ./data/UCR/Beef/Beef.zip
0%| | 0/432784 [00:00<?, ?it/s]
433152it [00:00, 4466983.11it/s]
Extracting ./data/UCR/Beef/Beef.zip to ./data/UCR/Beef
/home/vincent/miniconda3/envs/torchtime/lib/python3.9/site-packages/torchtime-0.0.1+8eabcd0-py3.9.egg/torchtime/io/ts.py:459: UserWarning: Meta information for '@dimensions' is missing. Inferring from data.
self.parse_body(line)
/home/vincent/miniconda3/envs/torchtime/lib/python3.9/site-packages/torchtime-0.0.1+8eabcd0-py3.9.egg/torchtime/datasets/ucruea.py:135: DataConversionWarning: Labels are not numeric and no explicit class mapping is provided. Please pass an explicit class mapping to the constructor. Using class labels parsed from dataset.
self.data, self.targets, self.classes = self._load_data()
Let us show some of the training spectrograms, for fun.
import matplotlib.pyplot as plt
def seriesshow(sequences, labels):
""" Plot a univariate time series.
"""
fig, ax = plt.subplots()
for series, label in zip(sequences, labels):
for dimension in series:
ax.plot(dimension, label=classes[label])
ax.legend()
ax.grid()
fig.show()
# get some random training sequences
dataiter = iter(trainloader)
sequences, labels = next(dataiter)
# show sequences
seriesshow(sequences, labels)
# print labels
print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size)))
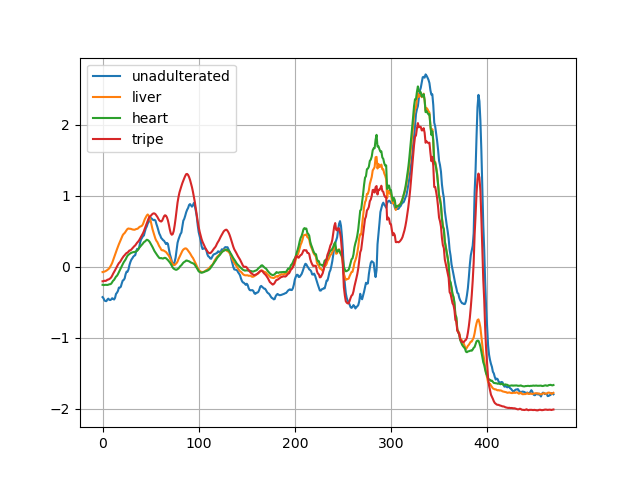
unadulterated liver heart tripe
2. Define an InceptionTime style classifier¶
We import the InceptionTime Model [Ismail Fawaz et al., 2020] available through
the torchtime.models package and initialize it such that it takes a 1-channel time series
as an input and maps it onto one of the five classes defined above.
import torchtime.models as models
net = models.InceptionTime(n_inputs=1, n_classes=5)
3. Define a Loss function and optimizer¶
Let’s use a Classification Cross-Entropy loss and SGD with momentum.
import torch.nn as nn
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
4. Train the network¶
This is when things start to get interesting. We simply have to loop over our data iterator, and feed the inputs to the network and optimize.
for epoch in range(10): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print(f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
print('Finished Training')
/home/vincent/miniconda3/envs/torchtime/lib/python3.9/site-packages/torch/autograd/__init__.py:173: UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 804: forward compatibility was attempted on non supported HW (Triggered internally at /opt/conda/conda-bld/pytorch_1659484806139/work/c10/cuda/CUDAFunctions.cpp:109.)
Variable._execution_engine.run_backward( # Calls into the C++ engine to run the backward pass
Finished Training
Let’s quickly save our trained model:
PATH = './beef_classifier.pth'
torch.save(net.state_dict(), PATH)
See here for more details on saving PyTorch models.
5. Test the network on the test data¶
We have trained the network for 10 passes over the training dataset (as it is a relatively small dataset with a 1:1 train/test split). But we need to check if the network has learnt anything at all.
We will check this by predicting the class label that the neural network outputs, and checking it against the ground-truth. If the prediction is correct, we add the sample to the list of correct predictions.
Okay, first step. Let us display a series from the test set to get familiar.
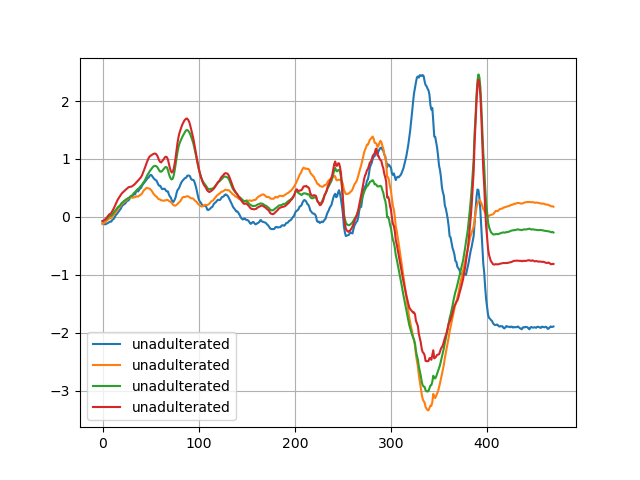
GroundTruth: unadulterated unadulterated unadulterated unadulterated
Next, let’s load back in our saved model (note: saving and re-loading the model wasn’t necessary here, we only did it to illustrate how to do so):
net = models.InceptionTime(n_inputs=1, n_classes=5)
net.load_state_dict(torch.load(PATH))
<All keys matched successfully>
Okay, now let us see what the neural network thinks these examples above are:
The outputs are energies for the 5 classes. The higher the energy for a class, the more the network thinks that the sequence is of the particular class. So, let’s get the index of the highest energy:
Predicted: heart unadulterated unadulterated unadulterated
The results seem pretty good.
Let us look at how the network performs on the whole dataset.
correct = 0
total = 0
# since we're not training, we don't need to calculate the gradients for our outputs
with torch.no_grad():
for data in testloader:
sequences, labels = data
# calculate outputs by running sequences through the network
outputs = net(sequences)
# the class with the highest energy is what we choose as prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print(f'Accuracy of the network on the 30 test sequences: {100 * correct // total} %')
Accuracy of the network on the 30 test sequences: 26 %
That looks way better than chance, which is 20% accuracy (randomly picking a class out of 5 classes). Seems like the network learnt something.
Hmmm, what are the classes that performed well, and the classes that did not perform well:
# prepare to count predictions for each class
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
# again no gradients needed
with torch.no_grad():
for data in testloader:
sequences, labels = data
outputs = net(sequences)
_, predictions = torch.max(outputs, 1)
# collect the correct predictions for each class
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
# print accuracy for each class
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print(f'Accuracy for class: {classname:5s} is {accuracy:.1f} %')
Accuracy for class: unadulterated is 83.3 %
Accuracy for class: heart is 33.3 %
Accuracy for class: kidney is 0.0 %
Accuracy for class: liver is 0.0 %
Accuracy for class: tripe is 16.7 %
Okay, so what next?
How do we run these neural networks on the GPU?
Training on GPU¶
Just like how you transfer a Tensor onto the GPU, you transfer the neural net onto the GPU.
Let’s first define our device as the first visible cuda device if we have CUDA available:
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# Assuming that we are on a CUDA machine, this should print a CUDA device:
print(device)
cpu
The rest of this section assumes that device is a CUDA device.
Then these methods will recursively go over all modules and convert their parameters and buffers to CUDA tensors:
net.to(device)
Remember that you will have to send the inputs and targets at every step to the GPU too:
Why don’t I notice MASSIVE speedup compared to CPU? Because your network is tiny.
Total running time of the script: ( 0 minutes 8.902 seconds)